This is a fixed-text formatted version of a Jupyter notebook.
You can contribute with your own notebooks in this GitHub repository.
Source files: spectrum_analysis.ipynb | spectrum_analysis.py
Spectral analysis with Gammapy¶
Introduction¶
This notebook explains in detail how to use the classes in gammapy.spectrum and related ones. Note, that there is also spectrum_pipe.ipynb which explains how to do the analysis using a high-level interface. This notebook is aimed at advanced users who want to script taylor-made analysis pipelines and implement new methods.
Based on a datasets of 4 Crab observations with H.E.S.S. (simulated events for now) we will perform a full region based spectral analysis, i.e. extracting source and background counts from certain regions, and fitting them using the forward-folding approach. We will use the following classes
Data handling:
- gammapy.data.DataStore
- gammapy.data.DataStoreObservation
- gammapy.data.ObservationStats
- gammapy.data.ObservationSummary
To extract the 1-dim spectral information:
- gammapy.spectrum.SpectrumObservation
- gammapy.spectrum.SpectrumExtraction
- gammapy.background.ReflectedRegionsBackgroundEstimator
For the global fit (using Sherpa and WSTAT in the background):
- gammapy.spectrum.SpectrumFit
- gammapy.spectrum.models.PowerLaw
- gammapy.spectrum.models.ExponentialCutoffPowerLaw
- gammapy.spectrum.models.LogParabola
To compute flux points (a.k.a. “SED” = “spectral energy distribution”)
- gammapy.spectrum.SpectrumResult
- gammapy.spectrum.FluxPoints
- gammapy.spectrum.SpectrumEnergyGroupMaker
- gammapy.spectrum.FluxPointEstimator
Feedback welcome!
Setup¶
As usual, we’ll start with some setup …
In [1]:
%matplotlib inline
import matplotlib.pyplot as plt
In [2]:
# Check package versions
import gammapy
import numpy as np
import astropy
import regions
import sherpa
print('gammapy:', gammapy.__version__)
print('numpy:', np.__version__)
print('astropy', astropy.__version__)
print('regions', regions.__version__)
print('sherpa', sherpa.__version__)
gammapy: 0.7.dev5129
numpy: 1.13.3
astropy 3.0.dev20290
regions 0.2
sherpa 4.9.1+12.g3626715
In [3]:
import astropy.units as u
from astropy.coordinates import SkyCoord, Angle
from astropy.table import vstack as vstack_table
from regions import CircleSkyRegion
from gammapy.data import DataStore, ObservationList
from gammapy.data import ObservationStats, ObservationSummary
from gammapy.background.reflected import ReflectedRegionsBackgroundEstimator
from gammapy.utils.energy import EnergyBounds
from gammapy.spectrum import SpectrumExtraction, SpectrumObservation, SpectrumFit, SpectrumResult
from gammapy.spectrum.models import PowerLaw, ExponentialCutoffPowerLaw, LogParabola
from gammapy.spectrum import FluxPoints, SpectrumEnergyGroupMaker, FluxPointEstimator
from gammapy.image import SkyImage
Configure logger¶
Most high level classes in gammapy have the possibility to turn on logging or debug output. We well configure the logger in the following. For more info see https://docs.python.org/2/howto/logging.html#logging-basic-tutorial
In [4]:
# Setup the logger
import logging
logging.basicConfig()
log = logging.getLogger('gammapy.spectrum')
log.setLevel(logging.WARNING)
Load Data¶
First, we select and load some H.E.S.S. observations of the Crab nebula (simulated events for now).
We will access the events, effective area, energy dispersion, livetime and PSF for containement correction.
In [5]:
DATA_DIR = '$GAMMAPY_EXTRA/datasets/hess-crab4-hd-hap-prod2'
datastore = DataStore.from_dir(DATA_DIR)
obs_ids = [23523, 23526, 23559, 23592]
obs_list = datastore.obs_list(obs_ids)
Define Target Region¶
The next step is to define a signal extraction region, also known as on
region. In the simplest case this is just a
CircleSkyRegion,
but here we will use the Target class in gammapy that is useful for
book-keeping if you run several analysis in a script.
In [6]:
target_position = SkyCoord(ra=83.63, dec=22.01, unit='deg', frame='icrs')
on_region_radius = Angle('0.11 deg')
on_region = CircleSkyRegion(center=target_position, radius=on_region_radius)
Load exclusion mask¶
Most analysis will require a mask to exclude regions with possible gamma-ray signal from the background estimation procedure. For simplicity, we will use a pre-cooked exclusion mask from gammapy-extra which includes (or rather excludes) all source listed in the TeVCat and cutout only the region around the crab.
TODO: Change to gamma-cat
In [7]:
EXCLUSION_FILE = '$GAMMAPY_EXTRA/datasets/exclusion_masks/tevcat_exclusion.fits'
allsky_mask = SkyImage.read(EXCLUSION_FILE)
exclusion_mask = allsky_mask.cutout(
position=on_region.center,
size=Angle('6 deg'),
)
Estimate background¶
Next we will manually perform a background estimate by placing reflected regions around the pointing position and looking at the source statistics. This will result in a gammapy.background.BackgroundEstimate that serves as input for other classes in gammapy.
In [8]:
background_estimator = ReflectedRegionsBackgroundEstimator(
obs_list=obs_list,
on_region=on_region,
exclusion_mask = exclusion_mask)
background_estimator.run()
print(background_estimator.result[0])
BackgroundEstimate
Method: Reflected Regions
on region
Region: CircleSkyRegion
center: <SkyCoord (ICRS): (ra, dec) in deg
( 83.63, 22.01)>
radius: 0.11 deg
EventList info:
- Number of events: 172
- Median energy: 1.2035582065582275 TeV
- Median azimuth: 0.0
- Median altitude: 0.0
off region
[<CircleSkyRegion(<SkyCoord (Galactic): (l, b) in deg
( 184.52251966, -6.24161087)>, radius=0.11040258105103296 deg)>, <CircleSkyRegion(<SkyCoord (Galactic): (l, b) in deg
( 184.65000376, -6.42189598)>, radius=0.11040258105103296 deg)>, <CircleSkyRegion(<SkyCoord (Galactic): (l, b) in deg
( 184.84295448, -6.52925025)>, radius=0.11040258105103296 deg)>, <CircleSkyRegion(<SkyCoord (Galactic): (l, b) in deg
( 185.06336026, -6.54252475)>, radius=0.11040258105103296 deg)>, <CircleSkyRegion(<SkyCoord (Galactic): (l, b) in deg
( 185.26780087, -6.45910437)>, radius=0.11040258105103296 deg)>, <CircleSkyRegion(<SkyCoord (Galactic): (l, b) in deg
( 185.41600122, -6.29542305)>, radius=0.11040258105103296 deg)>, <CircleSkyRegion(<SkyCoord (Galactic): (l, b) in deg
( 185.47876565, -6.08372622)>, radius=0.11040258105103296 deg)>, <CircleSkyRegion(<SkyCoord (Galactic): (l, b) in deg
( 185.44372948, -5.86571845)>, radius=0.11040258105103296 deg)>, <CircleSkyRegion(<SkyCoord (Galactic): (l, b) in deg
( 185.31779489, -5.68434757)>, radius=0.11040258105103296 deg)>, <CircleSkyRegion(<SkyCoord (Galactic): (l, b) in deg
( 185.12577116, -5.57534387)>, radius=0.11040258105103296 deg)>, <CircleSkyRegion(<SkyCoord (Galactic): (l, b) in deg
( 184.90548722, -5.56018125)>, radius=0.11040258105103296 deg)>]
EventList info:
- Number of events: 51
- Median energy: 1.2129952907562256 TeV
- Median azimuth: 0.0
- Median altitude: 0.0
In [9]:
plt.figure(figsize=(8,8))
background_estimator.plot()
Out[9]:
(<matplotlib.figure.Figure at 0x10b04c4e0>,
<matplotlib.axes._subplots.WCSAxesSubplot at 0x10b053a90>,
None)
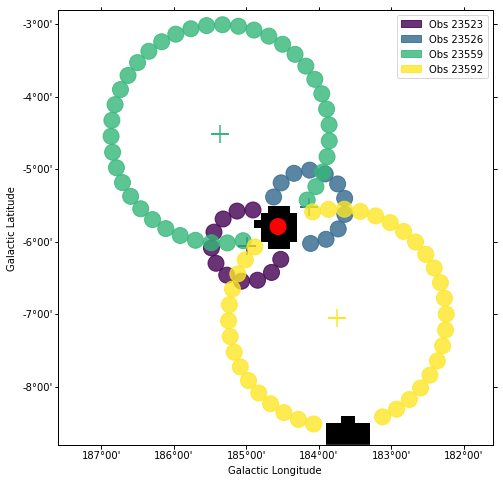
Source statistic¶
Next we’re going to look at the overall source statistics in our signal region. For more info about what debug plots you can create check out the ObservationSummary class.
In [10]:
stats = []
for obs, bkg in zip(obs_list, background_estimator.result):
stats.append(ObservationStats.from_obs(obs, bkg))
print(stats[1])
obs_summary = ObservationSummary(stats)
fig = plt.figure(figsize=(10,6))
ax1=fig.add_subplot(121)
obs_summary.plot_excess_vs_livetime(ax=ax1)
ax2=fig.add_subplot(122)
obs_summary.plot_significance_vs_livetime(ax=ax2)
*** Observation summary report ***
Observation Id: 23526
Livetime: 0.437 h
On events: 168
Off events: 58
Alpha: 0.091
Bkg events in On region: 5.27
Excess: 162.73
Excess / Background: 30.86
Gamma rate: 6.41 1 / min
Bkg rate: 0.20 1 / min
Sigma: 24.24
Out[10]:
<matplotlib.axes._subplots.AxesSubplot at 0x104f508d0>
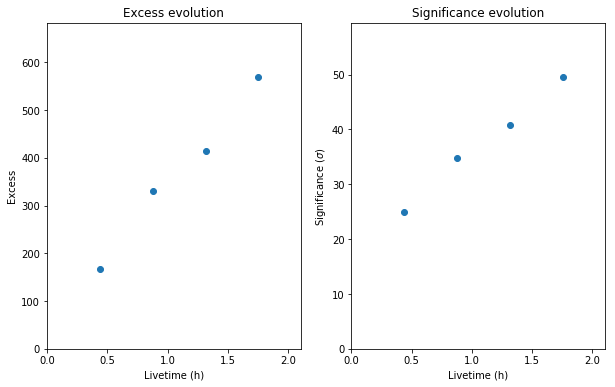
Extract spectrum¶
Now, we’re going to extract a spectrum using the SpectrumExtraction class. We provide the reconstructed energy binning we want to use. It is expected to be a Quantity with unit energy, i.e. an array with an energy unit. We use a utility function to create it. We also provide the true energy binning to use.
In [11]:
e_reco = EnergyBounds.equal_log_spacing(0.1, 40, 40, unit='TeV')
e_true = EnergyBounds.equal_log_spacing(0.05, 100., 200, unit='TeV')
Instantiate a SpectrumExtraction object that will do the extraction. The containment_correction parameter is there to allow for PSF leakage correction if one is working with full enclosure IRFs. We also compute a threshold energy and store the result in OGIP compliant files (pha, rmf, arf). This last step might be omitted though.
In [12]:
ANALYSIS_DIR = 'crab_analysis'
extraction = SpectrumExtraction(
obs_list=obs_list,
bkg_estimate=background_estimator.result,
containment_correction=False,
)
extraction.run()
# Add a condition on correct energy range in case it is not set by default
extraction.compute_energy_threshold(method_lo='area_max', area_percent_lo=10.0)
print(extraction.observations[0])
# Write output in the form of OGIP files: PHA, ARF, RMF, BKG
# extraction.run(obs_list=obs_list, bkg_estimate=background_estimator.result, outdir=ANALYSIS_DIR)
/Users/deil/Library/Python/3.6/lib/python/site-packages/astropy/units/quantity.py:634: RuntimeWarning: invalid value encountered in true_divide
result = super().__array_ufunc__(function, method, *arrays, **kwargs)
*** Observation summary report ***
Observation Id: 23523
Livetime: 0.439 h
On events: 139
Off events: 44
Alpha: 0.091
Bkg events in On region: 4.00
Excess: 135.00
Excess / Background: 33.75
Gamma rate: 0.13 1 / min
Bkg rate: 0.00 1 / min
Sigma: 22.28
energy range: 0.68 TeV - 100.00 TeV
Look at observations¶
Now we will look at the files we just created. We will use the
SpectrumObservation
object that are still in memory from the extraction step. Note, however,
that you could also read them from disk if you have written them in the
step above . The ANALYSIS_DIR folder contains 4 FITS files for
each observation. These files are described in detail at
https://gamma-astro-data-formats.readthedocs.io/en/latest/ogip/index.html.
In short they correspond to the on vector, the off vector, the effectie
area, and the energy dispersion.
In [13]:
#filename = ANALYSIS_DIR + '/ogip_data/pha_obs23523.fits'
#obs = SpectrumObservation.read(filename)
# Requires IPython widgets
#_ = extraction.observations.peek()
extraction.observations[0].peek()
/opt/local/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/matplotlib/colors.py:1238: UserWarning: Power-law scaling on negative values is ill-defined, clamping to 0.
warnings.warn("Power-law scaling on negative values is "
/opt/local/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/matplotlib/colors.py:1199: RuntimeWarning: invalid value encountered in power
np.power(resdat, gamma, resdat)
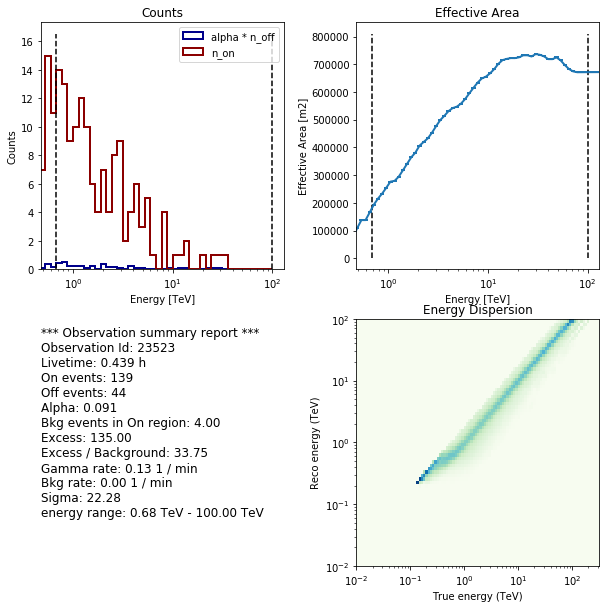
Fit spectrum¶
Now we’ll fit a global model to the spectrum. First we do a joint likelihood fit to all observations. If you want to stack the observations see below. We will also produce a debug plot in order to show how the global fit matches one of the individual observations.
In [14]:
model = PowerLaw(
index=2 * u.Unit(''),
amplitude=2e-11 * u.Unit('cm-2 s-1 TeV-1'),
reference=1 * u.TeV,
)
joint_fit = SpectrumFit(obs_list=extraction.observations, model=model)
joint_fit.fit()
joint_fit.est_errors()
#fit.run(outdir = ANALYSIS_DIR)
joint_result = joint_fit.result
/Users/deil/code/gammapy/gammapy/stats/fit_statistics.py:161: RuntimeWarning: divide by zero encountered in log
term2_ = - n_on * np.log(mu_sig + alpha * mu_bkg)
/Users/deil/code/gammapy/gammapy/stats/fit_statistics.py:166: RuntimeWarning: divide by zero encountered in log
term3_ = - n_off * np.log(mu_bkg)
/Users/deil/code/gammapy/gammapy/stats/fit_statistics.py:203: RuntimeWarning: divide by zero encountered in log
term1 = - n_on * (1 - np.log(n_on))
/Users/deil/code/gammapy/gammapy/stats/fit_statistics.py:204: RuntimeWarning: divide by zero encountered in log
term2 = - n_off * (1 - np.log(n_off))
In [15]:
ax0, ax1 = joint_result[0].plot(figsize=(8,8))
ax0.set_ylim(0, 20)
print(joint_result[0])
Fit result info
---------------
Model: PowerLaw
Parameters:
name value error unit min max frozen
--------- --------- --------- --------------- --- --- ------
index 2.178e+00 4.441e-02 nan nan False
amplitude 2.012e-11 1.020e-12 1 / (cm2 s TeV) nan nan False
reference 1.000e+00 0.000e+00 TeV nan nan True
Covariance:
name/name index amplitude
--------- -------- ---------
index 0.00197 2.21e-14
amplitude 2.21e-14 1.04e-24
Statistic: 34.777 (wstat)
Fit Range: [ 0.68129207 100. ] TeV
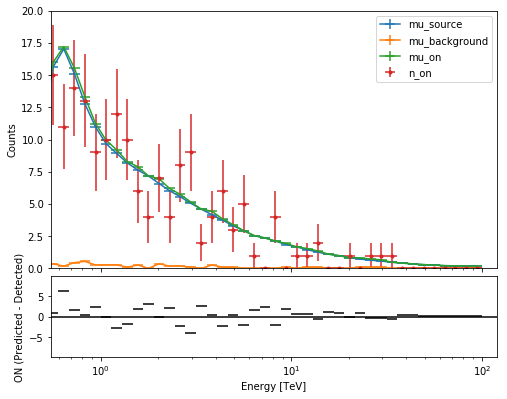
Compute Flux Points¶
To round up out analysis we can compute flux points by fitting the norm of the global model in energy bands. We’ll use a fixed energy binning for now.
In [16]:
# Define energy binning
ebounds = [0.3, 1.1, 3, 10.1, 30] * u.TeV
stacked_obs = extraction.observations.stack()
seg = SpectrumEnergyGroupMaker(obs=stacked_obs)
seg.compute_range_safe()
seg.compute_groups_fixed(ebounds=ebounds)
print(seg.groups)
SpectrumEnergyGroups:
Info including underflow- and overflow bins:
Number of groups: 6
Bin range: (0, 71)
Energy range: EnergyRange(min=0.01 TeV, max=100.0 TeV)
/Users/deil/code/gammapy/gammapy/stats/poisson.py:383: RuntimeWarning: divide by zero encountered in double_scalars
temp = (alpha + 1) / (n_on + n_off)
/Users/deil/code/gammapy/gammapy/stats/poisson.py:385: RuntimeWarning: divide by zero encountered in log
m = n_off * log(n_off * temp)
/Users/deil/code/gammapy/gammapy/stats/poisson.py:384: RuntimeWarning: divide by zero encountered in log
l = n_on * log(n_on * temp / alpha)
In [17]:
fpe = FluxPointEstimator(
obs=stacked_obs,
groups=seg.groups,
model=joint_result[0].model,
)
fpe.compute_points()
/Users/deil/code/gammapy/gammapy/stats/fit_statistics.py:161: RuntimeWarning: divide by zero encountered in log
term2_ = - n_on * np.log(mu_sig + alpha * mu_bkg)
/Users/deil/code/gammapy/gammapy/stats/fit_statistics.py:166: RuntimeWarning: divide by zero encountered in log
term3_ = - n_off * np.log(mu_bkg)
/Users/deil/code/gammapy/gammapy/stats/fit_statistics.py:203: RuntimeWarning: divide by zero encountered in log
term1 = - n_on * (1 - np.log(n_on))
/Users/deil/code/gammapy/gammapy/stats/fit_statistics.py:204: RuntimeWarning: divide by zero encountered in log
term2 = - n_off * (1 - np.log(n_off))
In [18]:
fpe.flux_points.plot()
fpe.flux_points.table
Out[18]:
| e_ref | e_min | e_max | dnde | dnde_err | dnde_ul | is_ul | sqrt_ts | dnde_errp | dnde_errn |
|---|---|---|---|---|---|---|---|---|---|
| TeV | TeV | TeV | 1 / (cm2 s TeV) | 1 / (cm2 s TeV) | 1 / (cm2 s TeV) | 1 / (cm2 s TeV) | 1 / (cm2 s TeV) | ||
| float64 | float64 | float64 | float64 | float64 | float64 | bool | float64 | float64 | float64 |
| 0.681292069058 | 0.464158883361 | 1.0 | 3.7087890856e-11 | 2.98925024997e-12 | 4.33476015219e-11 | False | 24.8667543824 | 2.9833525432e-12 | 2.94494024816e-12 |
| 1.6681005372 | 1.0 | 2.78255940221 | 8.1570462151e-12 | 5.40511435651e-13 | 9.29533532901e-12 | False | 32.695252187 | 5.65789940379e-13 | 5.12020688833e-13 |
| 5.2749970637 | 2.78255940221 | 10.0 | 5.95234607581e-13 | 5.74566970764e-14 | 7.18471748878e-13 | False | 21.8282192748 | 5.8807378136e-14 | 5.52229297328e-14 |
| 16.681005372 | 10.0 | 27.8255940221 | 3.18839971318e-14 | 7.40994324674e-15 | 4.89510875816e-14 | False | 8.58047038384 | 7.9064762535e-15 | 6.85090500174e-15 |
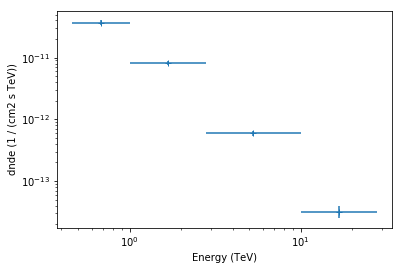
The final plot with the best fit model and the flux points can be quickly made like this
In [19]:
spectrum_result = SpectrumResult(
points=fpe.flux_points,
model=joint_result[0].model,
)
ax0, ax1 = spectrum_result.plot(
energy_range=joint_fit.result[0].fit_range,
energy_power=2, flux_unit='erg-1 cm-2 s-1',
fig_kwargs=dict(figsize=(8,8)),
point_kwargs=dict(color='navy')
)
ax0.set_xlim(0.4, 50)
Out[19]:
(0.4, 50)
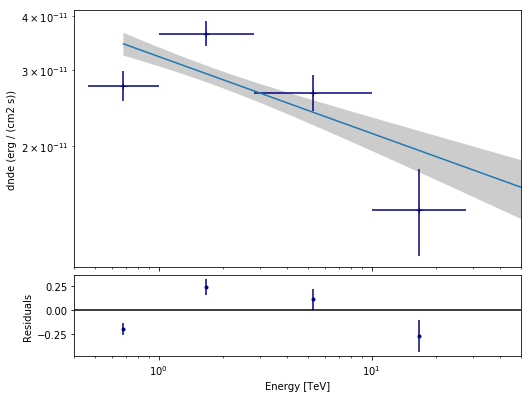
Stack observations¶
And alternative approach to fitting the spectrum is stacking all observations first and the fitting a model to the stacked observation. This works as follows. A comparison to the joint likelihood fit is also printed.
In [20]:
stacked_obs = extraction.observations.stack()
stacked_fit = SpectrumFit(obs_list=stacked_obs, model=model)
stacked_fit.fit()
stacked_fit.est_errors()
stacked_result = stacked_fit.result
print(stacked_result[0])
stacked_table = stacked_result[0].to_table(format='.3g')
stacked_table['method'] = 'stacked'
joint_table = joint_result[0].to_table(format='.3g')
joint_table['method'] = 'joint'
total_table = vstack_table([stacked_table, joint_table])
print(total_table['method', 'index', 'index_err', 'amplitude', 'amplitude_err'])
/Users/deil/code/gammapy/gammapy/stats/fit_statistics.py:161: RuntimeWarning: divide by zero encountered in log
term2_ = - n_on * np.log(mu_sig + alpha * mu_bkg)
/Users/deil/code/gammapy/gammapy/stats/fit_statistics.py:166: RuntimeWarning: divide by zero encountered in log
term3_ = - n_off * np.log(mu_bkg)
/Users/deil/code/gammapy/gammapy/stats/fit_statistics.py:203: RuntimeWarning: divide by zero encountered in log
term1 = - n_on * (1 - np.log(n_on))
/Users/deil/code/gammapy/gammapy/stats/fit_statistics.py:204: RuntimeWarning: divide by zero encountered in log
term2 = - n_off * (1 - np.log(n_off))
Fit result info
---------------
Model: PowerLaw
Parameters:
name value error unit min max frozen
--------- --------- --------- --------------- --- --- ------
index 2.177e+00 4.432e-02 nan nan False
amplitude 2.012e-11 1.020e-12 1 / (cm2 s TeV) nan nan False
reference 1.000e+00 0.000e+00 TeV nan nan True
Covariance:
name/name index amplitude
--------- -------- ---------
index 0.00196 2.21e-14
amplitude 2.21e-14 1.04e-24
Statistic: 81.604 (wstat)
Fit Range: [ 0.46415888 100. ] TeV
method index index_err amplitude amplitude_err
1 / (cm2 s TeV) 1 / (cm2 s TeV)
------- ----- --------- --------------- ---------------
stacked 2.18 0.0443 2.01e-11 1.02e-12
joint 2.18 0.0444 2.01e-11 1.02e-12
Exercises¶
Some things we might do:
- Fit a different spectral model (ECPL or CPL or …)
- Use different method or parameters to compute the flux points
- Do a chi^2 fit to the flux points and compare
TODO: give pointers how to do this (and maybe write a notebook with solutions)
In [21]:
# Start exercises here
What next?¶
In this tutorial we learned how to extract counts spectra from an event list and generate the corresponding IRFs. Then we fitted a model to the observations and also computed flux points.
Here’s some suggestions where to go next:
- if you want think this is way too complicated and just want to run a quick analysis check out this notebook
- if you interested in available fit statistics checkout gammapy.stats
- if you want to simulate spectral look at this tutorial
- if you want to compare your spectra to e.g. Fermi spectra published in catalogs have a look at this