This is a fixed-text formatted version of a Jupyter notebook
Try online

You can contribute with your own notebooks in this GitHub repository.
Source files: cta_sensitivity.ipynb | cta_sensitivity.py
Estimation of the CTA point source sensitivity¶
Introduction¶
This notebook explains how to estimate the CTA sensitivity for a point-like IRF at a fixed zenith angle and fixed offset using the full containement IRFs distributed for the CTA 1DC. The significativity is computed for a 1D analysis (On-OFF regions) and the LiMa formula.
We use here an approximate approach with an energy dependent integration radius to take into account the variation of the PSF. We will first determine the 1D IRFs including a containment correction.
We will be using the following Gammapy class:
Setup¶
As usual, we’ll start with some setup …
[1]:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
[2]:
import astropy.units as u
from astropy.coordinates import Angle, SkyCoord
from regions import CircleSkyRegion
from gammapy.irf import load_cta_irfs
from gammapy.makers import SpectrumDatasetMaker
from gammapy.data import Observation
from gammapy.estimators import SensitivityEstimator
from gammapy.datasets import SpectrumDataset, SpectrumDatasetOnOff
from gammapy.maps import MapAxis
Define analysis region and energy binning¶
Here we assume a source at 0.5 degree from pointing position. We perform a simple energy independent extraction for now with a radius of 0.1 degree.
[3]:
center = SkyCoord("0 deg", "0.5 deg")
region = CircleSkyRegion(center=center, radius=0.1 * u.deg)
e_reco = MapAxis.from_energy_bounds("0.03 TeV", "30 TeV", nbin=20)
e_true = MapAxis.from_energy_bounds("0.01 TeV", "100 TeV", nbin=100)
empty_dataset = SpectrumDataset.create(
e_reco=e_reco.edges, e_true=e_true.edges, region=region
)
Load IRFs and prepare dataset¶
We extract the 1D IRFs from the full 3D IRFs provided by CTA.
[4]:
irfs = load_cta_irfs(
"$GAMMAPY_DATA/cta-1dc/caldb/data/cta/1dc/bcf/South_z20_50h/irf_file.fits"
)
pointing = SkyCoord("0 deg", "0 deg")
obs = Observation.create(pointing=pointing, irfs=irfs, livetime="5 h")
[5]:
spectrum_maker = SpectrumDatasetMaker(
selection=["aeff", "edisp", "background"]
)
dataset = spectrum_maker.run(empty_dataset, obs)
Now we correct for the energy dependent region size:
[6]:
containment = 0.68
# correct effective area
dataset.aeff.data.data *= containment
# correct background estimation
on_radii = obs.psf.containment_radius(
energy=e_reco.center, theta=0.5 * u.deg, fraction=containment
)[0]
factor = (1 - np.cos(on_radii)) / (1 - np.cos(region.radius))
dataset.background.data *= factor.value.reshape((-1, 1, 1))
And finally define a SpectrumDatasetOnOff with an alpha of 0.2. The off counts are created from the background model:
[7]:
dataset_on_off = SpectrumDatasetOnOff.from_spectrum_dataset(
dataset=dataset, acceptance=1, acceptance_off=5
)
Compute sensitivity¶
We impose a minimal number of expected signal counts of 5 per bin and a minimal significance of 3 per bin. We assume an alpha of 0.2 (ratio between ON and OFF area). We then run the sensitivity estimator.
[8]:
sensitivity_estimator = SensitivityEstimator(gamma_min=5, sigma=3)
sensitivity_table = sensitivity_estimator.run(dataset_on_off)
Results¶
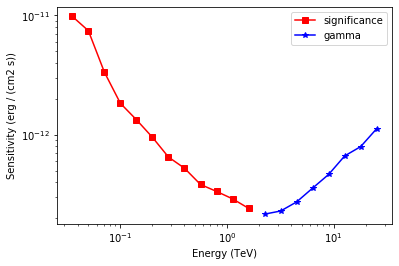
The results are given as an Astropy table. A column criterion allows to distinguish bins where the significance is limited by the signal statistical significance from bins where the sensitivity is limited by the number of signal counts. This is visible in the plot below.
[9]:
# Show the results table
sensitivity_table
[9]:
| energy | e2dnde | excess | background | criterion |
|---|---|---|---|---|
| TeV | erg / (cm2 s) | |||
| float64 | float64 | float64 | float64 | bytes12 |
| 0.0356551 | 9.81443e-12 | 199.602 | 3611.86 | significance |
| 0.0503641 | 7.44863e-12 | 141.851 | 1808.46 | significance |
| 0.0711412 | 3.34717e-12 | 94.6081 | 792.485 | significance |
| 0.10049 | 1.83443e-12 | 67.225 | 392.809 | significance |
| 0.141945 | 1.3367e-12 | 47.1992 | 188.424 | significance |
| 0.200503 | 9.51624e-13 | 31.7001 | 81.2163 | significance |
| 0.283218 | 6.50443e-13 | 21.7761 | 35.9296 | significance |
| 0.400056 | 5.2438e-13 | 15.1912 | 15.9406 | significance |
| 0.565095 | 3.83121e-13 | 11.1615 | 7.6638 | significance |
| 0.798218 | 3.35256e-13 | 8.29778 | 3.60441 | significance |
| 1.12751 | 2.90424e-13 | 6.55695 | 1.87455 | significance |
| 1.59265 | 2.42006e-13 | 5.69212 | 1.22178 | significance |
| 2.24968 | 2.16291e-13 | 5 | 0.78233 | gamma |
| 3.17776 | 2.29643e-13 | 5 | 0.499028 | gamma |
| 4.48871 | 2.73642e-13 | 5 | 0.340861 | gamma |
| 6.34047 | 3.57511e-13 | 5 | 0.202769 | gamma |
| 8.95615 | 4.65419e-13 | 5 | 0.0940542 | gamma |
| 12.6509 | 6.65067e-13 | 5 | 0.0507529 | gamma |
| 17.8699 | 7.96271e-13 | 5 | 0.0300523 | gamma |
| 25.2419 | 1.12581e-12 | 5 | 0.0137948 | gamma |
[10]:
# Save it to file (could use e.g. format of CSV or ECSV or FITS)
# sensitivity_table.write('sensitivity.ecsv', format='ascii.ecsv')
[11]:
# Plot the sensitivity curve
t = sensitivity_table
is_s = t["criterion"] == "significance"
plt.plot(
t["energy"][is_s],
t["e2dnde"][is_s],
"s-",
color="red",
label="significance",
)
is_g = t["criterion"] == "gamma"
plt.plot(
t["energy"][is_g], t["e2dnde"][is_g], "*-", color="blue", label="gamma"
)
plt.loglog()
plt.xlabel(f"Energy ({t['energy'].unit})")
plt.ylabel(f"Sensitivity ({t['e2dnde'].unit})")
plt.legend();
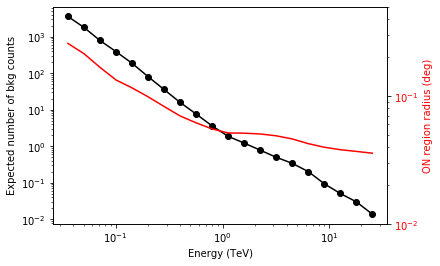
We add some control plots showing the expected number of background counts per bin and the ON region size cut (here the 68% containment radius of the PSF).
[12]:
# Plot expected number of counts for signal and background
fig, ax1 = plt.subplots()
# ax1.plot( t["energy"], t["excess"],"o-", color="red", label="signal")
ax1.plot(
t["energy"], t["background"], "o-", color="black", label="blackground"
)
ax1.loglog()
ax1.set_xlabel(f"Energy ({t['energy'].unit})")
ax1.set_ylabel("Expected number of bkg counts")
ax2 = ax1.twinx()
ax2.set_ylabel(f"ON region radius ({on_radii.unit})", color="red")
ax2.semilogy(t["energy"], on_radii, color="red", label="PSF68")
ax2.tick_params(axis="y", labelcolor="red")
ax2.set_ylim(0.01, 0.5)
[12]:
(0.01, 0.5)
Exercises¶
Also compute the sensitivity for a 20 hour observation
Compare how the sensitivity differs between 5 and 20 hours by plotting the ratio as a function of energy.