stats - Statistics¶
Introduction¶
gammapy.stats holds statistical estimators, fit statistics and algorithms
commonly used in gamma-ray astronomy.
It is mostly concerned with the evaluation of one or several observations that count events in a given region and time window, i.e. with Poisson-distributed counts measurements.
General notions¶
Counts and fit statistics¶
Gamma-ray measurements are counts, n_on, containing both signal and background events.
Estimation of number of signal events or of quantities in physical models is done through Poisson likelihood functions, the fit statistics. In gammapy, they are all log-likelihood functions normalized like chi-squares, i.e. if \(L\) is the likelihood function used, they follow the expression \(2 \times log L\).
When the expected number of background events, mu_bkg is known, the statistic function
is Cash (see Cash : Poisson data with background model). When the number of background events is unknown, one has to
use a background estimate n_bkg taken from an OFF measurement where only background events
are expected. In this case, the statistic function is WStat (see WStat : Poisson data with background measurement).
These statistic functions are at the heart of the model fitting approach in gammapy. They are used to estimate the best fit values of model parameters and their associated confidence intervals.
They are used also to estimate the excess counts significance, i.e. the probability that
a given number of measured events n_on actually contains some signal events \(n_{excess}\),
as well as the errors associated to this estimated number of signal counts.
Estimating Delta TS¶
A classical approach to modeling and fitting relies on hypothesis testing. One wants to estimate whether an hypothesis \(H_1\) is statistically preferred over the reference, or null-hypothesis, \(H_0\).
The maximum log-likelihood ratio test provides a way to estimate the p-value of the data following \(H_1\) rather than \(H_0\), when the two hypotheses are nested. We note this ratio \(\lambda = \frac{max L(X|{H_1})}{max L(X|H_0)}\)
The Wilks theorem shows that under some hypothesis, \(-2 \log \lambda\) assymptotically follows a \(\chi^2\) distribution with \(n_{dof}\) degrees of freedom, where \(n_{dof}\) is the difference of free parameters between \(H_1\) and \(H_0\).
With the definition the fit statistics \(-2 \log \lambda\) is simply the difference of the fit statistic values for the two hypotheses, the delta TS (for test statistic). Hence, \(\Delta TS\) follows \(\chi^2\) distribution with \(n_{dof}\) degrees of freedom. In particular, with only one degree of freedom (e.g. intensity of a signal), on can estimate the statistical significance in terms of number of \(\sigma\) as \(\sqrt{\Delta TS}\).
Counts statistics classes¶
To estimate the excess counts significance and errors, gammapy uses two classes for Poisson counts with
and without known background: CashCountsStatistic and WStatCountsStatistic
We show below how to use them.
Cash counts statistic¶
Excess and Significance¶
Assume one measured \(n_{on} = 13\) counts in a region where one suspects a source might be present. if the expected number of background events is known (here e.g. \(\mu_{bkg}=9.5\)), one can use the Cash statistic to estimate the signal or excess number, its statistical significance as well as the confidence interval on the true signal value.
>>> from gammapy.stats import CashCountsStatistic
>>> stat = CashCountsStatistic(n_on=13, mu_bkg=5.5)
>>> stat.excess
7.5
>>> stat.error
3.605551275463989
>>> stat.delta_ts
7.365232895800901
>>> stat.significance
2.7138962573762653
>>> stat.p_value
0.006649698694909719
The error is the symmetric error obtained from the covariance of the statistic function, here \(\sqrt{n_{on}}\). The significance is the square root of the \(\Delta TS\), multiplied by the sign of the excess, which is equivalent to the Li & Ma significance for known background.
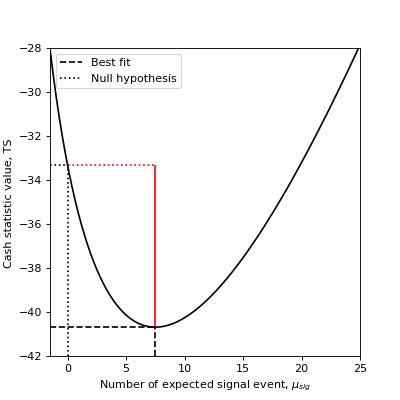
To see how the \(\Delta TS\), relates to the statistic function, we plot below the profile of the Cash statistic as a function of the expected signal events number.
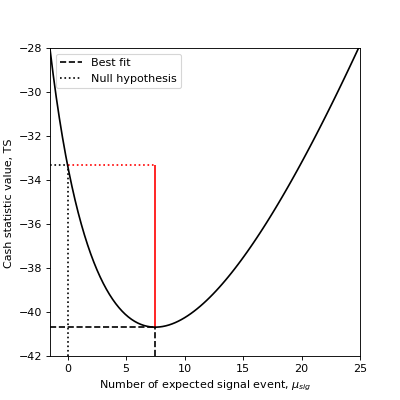{kind=link}
{kind=link}
Excess errors¶
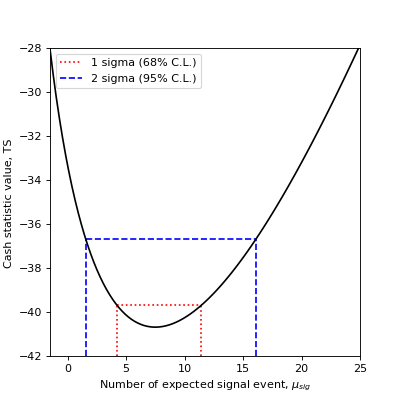
You can also compute the confidence interval for the true excess based on the statistic value: If you are interested in 68% (1 \(\sigma\)) and 95% (2 \(\sigma\)) confidence ranges:
>>> from gammapy.stats import CashCountsStatistic
>>> stat = CashCountsStatistic(n_on=13, mu_bkg=5.5)
>>> errn = count_statistic.compute_errn(1.)
>>> errp = count_statistic.compute_errp(1.)
>>> print(f"68% confidence range: {excess+errn} < mu < {excess+errp}")
68% confidence range: 4.219788441647667 < mu < 11.446309124623102
>>> errn_2sigma = count_statistic.compute_errn(2.)
>>> errp_2sigma = count_statistic.compute_errp(2.)
>>> print(f"95% confidence range: {excess+errn_2sigma} < mu < {excess+errp_2sigma}")
95% confidence range: 1.5559091942635206 < mu < 16.10168631791818
The 68% confidence interval (1 \(\sigma\)) is obtained by finding the expected signal values for which the TS variation is 1. The 95% confidence interval (2 \(\sigma\)) is obtained by finding the expected signal values for which the TS variation is \(2^2 = 4\).
On the following plot, we show how the 1 \(\sigma\) and 2 \(\sigma\) confidence errors relate to the Cash statistic profile.
{kind=link}
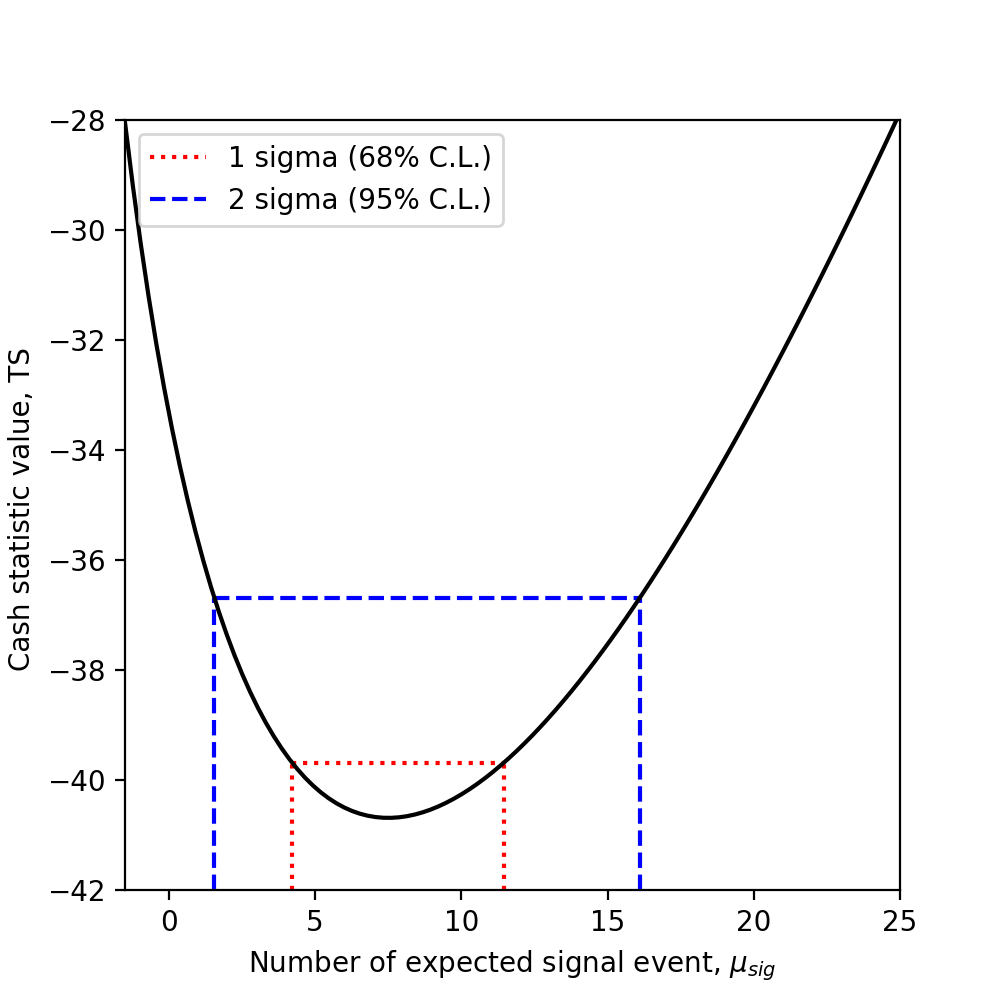{kind=link}
WStat counts statistic¶
Excess and Significance¶
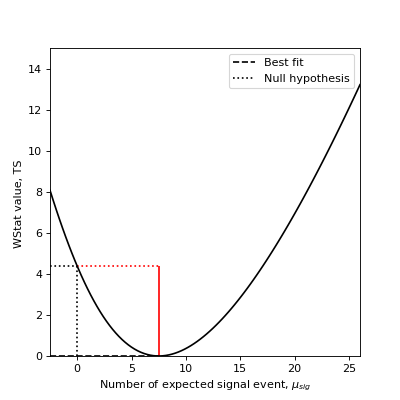
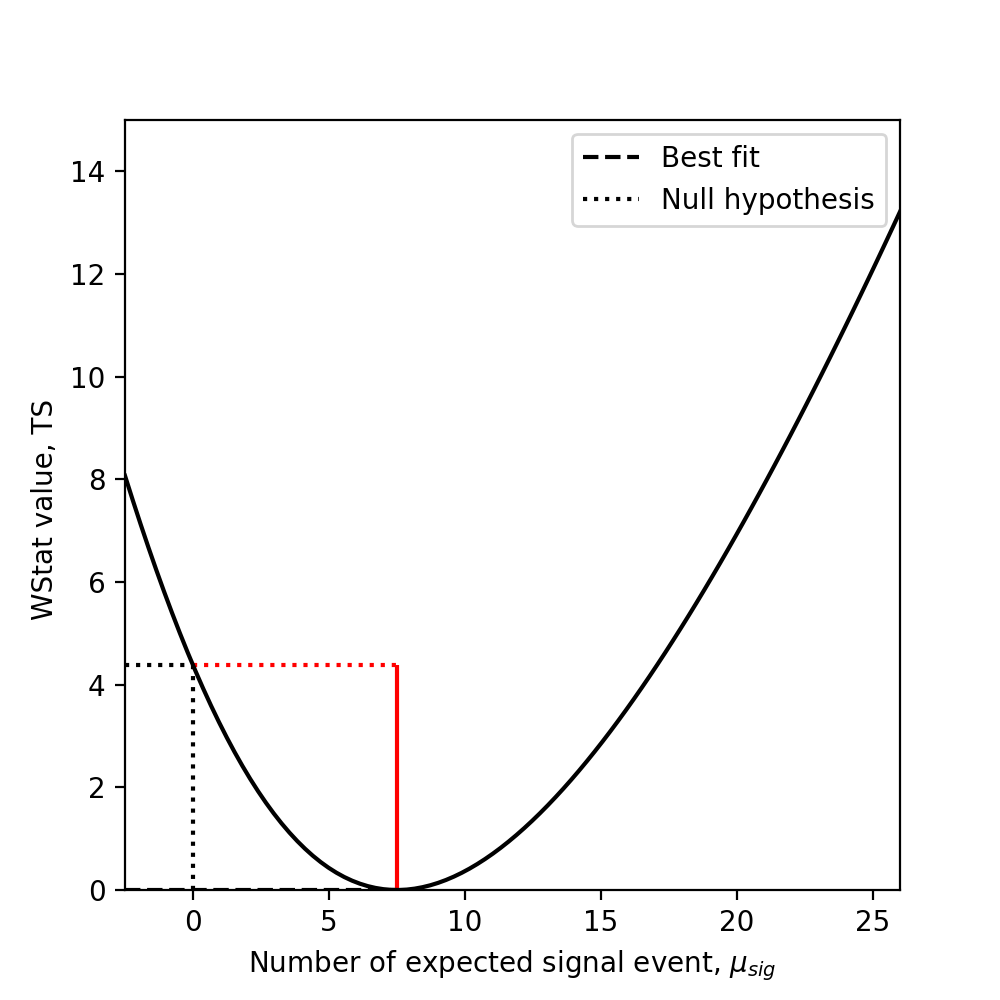
To measure the significance of an excess, one can directly use the delta TS of the measurement with and without the excess. Taking the square root of the result yields the so-called Li & Ma significance [LiMa1983] (see equation 17).
As an example, assume you measured \(n_{on} = 13\) counts in a region where you suspect a source might be present and \(n_{off} = 11\) counts in a background control region where you assume no source is present and that is \(a_{off}/a_{on}=2\) times larger than the on-region.
Here’s how you compute the statistical significance of your detection:
>>> from gammapy.stats import WStatCountsStatistic
>>> stat = WStatCountsStatistic(n_on=13, n_off=11, alpha=1./2)
>>> stat.excess
>>> stat.significance
{kind=link}
{kind=link}
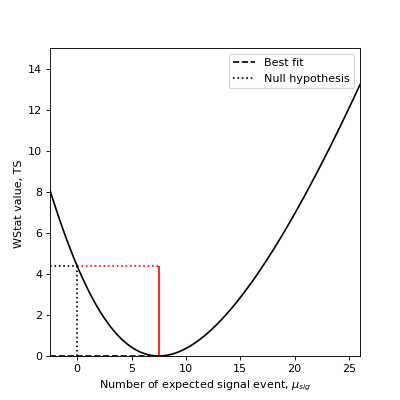
Conversely, if you know that the expected number of background events is \(\mu_{bkg}=9.5\), you can use the Cash statistic and obtain the Li & Ma significance for known background:
>>> from gammapy.stats import CashCountsStatistic
>>> stat = CashCountsStatistic(n_on=13, mu_bkg=5.5)
>>> stat.excess
>>> stat.significance
Excess errors¶
You can also compute the confidence interval for the true excess based on the statistic value:
If you are interested in 68% (1 \(\sigma\)) and 95% (1 \(\sigma\)) confidence errors:
>>> from gammapy.stats import CashCountsStatistic
>>> stat = CashCountsStatistic(n_on=13, mu_bkg=5.5)
>>> stat.compute_errn(1.)
-3.91606323
>>> stat.compute_errp(1.)
4.5823187389960225
>>> stat.compute_errn(2.)
-3.91606323
>>> stat.compute_errp(2.)
4.5823187389960225
The 68% confidence interval (1 \(\sigma\)) is obtained by finding the expected signal values for which the TS variation is 1. The 95% confidence interval (2 \(\sigma\)) is obtained by finding the expected signal values for which the TS variation is \(2^2 = 4\).
On the following plot, we show how the 1 \(\sigma\) and 2 \(\sigma\) confidence errors relate to the fit statistic profile. .. plot:: stats/plot_cash_errors.py
Note that confidence intervals can be computed in a more robust manner following [Feldman1998]. See Feldman and Cousins Confidence Intervals.
Notations¶
For on-off methods we use the following variable names following the notation in [Cousins2007]:
Variable |
Dataset attribute name |
Definition |
|---|---|---|
|
|
Total observed counts in the on region |
|
|
Total observed counts in the off region |
|
|
Total expected counts in the on region |
|
|
Total expected counts in the off region |
|
|
Signal expected counts in the on region |
|
|
Background expected counts in the on region |
|
|
Relative background exposure in the on region |
|
|
Relative background exposure in the off region |
|
|
Background efficiency ratio |
|
|
Background estimate in the on region |
The ON measurement, assumed to contain signal and background counts, \(n_{on}\) follows a Poisson random variable with expected value \(\mu_{on} = \mu_{sig} + \mu_{bkg}\).
The OFF measurement is assumed to contain only background counts, with an acceptance to background \(a_{off}\). This OFF measurement can be used to etimate the number of background counts in the ON measurement: \(n_{bkg} = \alpha\ n_{off}\) with \(\alpha = a_{on}/a_{off}\) the ratio of ON and OFF acceptances.
Therefore \(n_{off}\) follows a Poisson distribution with expected value :math:mu_{off} = mu_{bkg) / alpha
These are references describing the available methods: [LiMa1983], [Cash1979], [Stewart2009], [Rolke2005], [Feldman1998], [Cousins2007].
Using gammapy.stats¶
Reference/API¶
gammapy.stats Package¶
Statistics.
Functions¶
Compute bounds for the root of |
|
|
Cash statistic, for Poisson data. |
Summed cash fit statistics. |
|
|
C statistic, for Poisson data. |
Function to find root of. |
|
Convenience function that calculates the PDF for the user. |
|
Numerically choose bins a la Feldman Cousins ordering principle. |
|
|
Analytical acceptance interval for Gaussian with boundary at the origin. |
Analytical acceptance interval for Poisson process with background. |
|
|
Calculate the average upper limit for a confidence belt. |
|
Find the limit for a given x measurement. |
|
Push limits outwards as described in the FC paper. |
|
Find lower and upper limit from acceptance intervals. |
|
Goodness of fit terms for WSTAT. |
|
Background estimate |
|
W statistic, for Poisson data with Poisson background. |
Best fit amplitude using weighted least squares fit. |
Classes¶
|
Class to compute statistics (significance, asymmetric errors , ul) for Poisson distributed variable with known background. |
|
Class to compute statistics (significance, asymmetric errors , ul) for Poisson distributed variable with unknown background. |