This is a fixed-text formatted version of a Jupyter notebook
- Try online

- You can contribute with your own notebooks in this GitHub repository.
- Source files: background_model.ipynb | background_model.py
Make template background model¶
Introduction¶
In this tutorial, we will create a template background model from scratch. Often, background models are pre-computed and provided for analysis, but it’s educational to see how the sausage is made.
We will use the “off observations”, i.e. those without significant gamma-ray emission sources in the field of view from the H.E.S.S. first public test data release. This model could then be used in the analysis of sources from that dataset (not done here).
We will make a background model that is radially symmetric in the field of view, i.e. only depends on field of view offset angle and energy. At the end, we will save the model in the BKG_2D as defined in the spec.
Note that this is just a quick and dirty example. Actual background model production is done with more sophistication usually using 100s or 1000s of off runs, e.g. concerning non-radial symmetries, binning and smoothing of the distributions, and treating other dependencies such as zenith angle, telescope configuration or optical efficiency. Another aspect not shown here is how to use AGN observations to make background models, by cutting out the part of the field of view that contains gamma-rays from the AGN.
We will mainly be using the following classes:
- gammapy.data.DataStore to load the runs to use to build the bkg model.
- gammapy.irf.Background2D to represent and write the background model.
Setup¶
As always, we start the notebook with some setup and imports.
[1]:
%matplotlib inline
import matplotlib.pyplot as plt
[2]:
from copy import deepcopy
import numpy as np
import astropy.units as u
from astropy.io import fits
from astropy.table import Table, vstack
[3]:
from pathlib import Path
from gammapy.utils.nddata import sqrt_space
from gammapy.data import DataStore
from gammapy.irf import Background2D
Select off data¶
We start by selecting the observations used to estimate the background model.
In this case, we just take all “off runs” as defined in the observation table.
[4]:
data_store = DataStore.from_dir("$GAMMAPY_DATA/hess-dl3-dr1")
# Select just the off data runs
obs_table = data_store.obs_table
obs_table = obs_table[obs_table["TARGET_NAME"] == "Off data"]
observations = data_store.get_observations(obs_table["OBS_ID"])
print("Number of observations:", len(observations))
Number of observations: 45
Background model¶
The background model we will estimate is a differential background rate model in unit s-1 MeV-1 sr-1 as a function of reconstructed energy and field of fiew offset.
We estimate it by histogramming off data events and then smoothing a bit (not using a good method) to get a less noisy estimate. To get the differential rate, we divide by observation time and also take bin sizes into account to get the rate per energy and solid angle. So overall we fill two arrays called counts and exposure with exposure filled so that background_rate = counts / exposure will give the final background rate we’re interested in.
The processing can be done either one observation at a time, or first for counts and then for exposure. Either way is fine. Here we do one observation at a time, starting with empty histograms and then accumulating counts and exposure. Since this is a multi-step algorithm, we put the code to do this computation in a BackgroundModelEstimator class.
This functionality was already in Gammapy previously, and will be added back again soon, after gammapy.irf has been restructured and improved.
[5]:
class BackgroundModelEstimator:
def __init__(self, ebounds, offset):
self.counts = self._make_bkg2d(ebounds, offset, unit="")
self.exposure = self._make_bkg2d(ebounds, offset, unit="s MeV sr")
@staticmethod
def _make_bkg2d(ebounds, offset, unit):
ebounds = ebounds.to("MeV")
offset = offset.to("deg")
shape = len(ebounds) - 1, len(offset) - 1
return Background2D(
energy_lo=ebounds[:-1],
energy_hi=ebounds[1:],
offset_lo=offset[:-1],
offset_hi=offset[1:],
data=np.zeros(shape) * u.Unit(unit),
)
def run(self, observations):
for obs in observations:
self.fill_counts(obs)
self.fill_exposure(obs)
def fill_counts(self, obs):
events = obs.events
data = self.counts.data
counts = np.histogram2d(
x=events.energy.to("MeV"),
y=events.offset.to("deg"),
bins=(data.axes[0].edges, data.axes[1].edges),
)[0]
data.data += counts
def fill_exposure(self, obs):
data = self.exposure.data
energy_width = np.diff(data.axes[0].edges)
offset = data.axes[1].center
offset_width = np.diff(data.axes[1].edges)
solid_angle = 2 * np.pi * offset * offset_width
time = obs.observation_time_duration
exposure = time * energy_width[:, None] * solid_angle[None, :]
data.data += exposure
@property
def background_rate(self):
rate = deepcopy(self.counts)
rate.data.data /= self.exposure.data.data
return rate
[6]:
%%time
ebounds = np.logspace(-1, 2, 20) * u.TeV
offset = sqrt_space(start=0, stop=3, num=10) * u.deg
estimator = BackgroundModelEstimator(ebounds, offset)
estimator.run(observations)
CPU times: user 2 s, sys: 76.9 ms, total: 2.07 s
Wall time: 2.12 s
Let’s have a quick look at what we did …
[7]:
estimator.background_rate.plot()
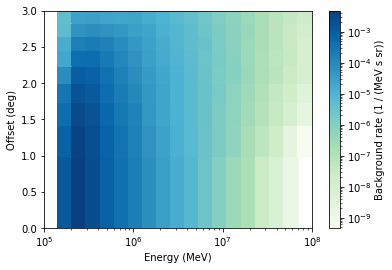
[8]:
# You could save the background model to a file like this
# estimator.background_rate.to_fits().writeto('background_model.fits', overwrite=True)
Zenith dependence¶
The background models used in H.E.S.S. usually depend on the zenith angle of the observation. That kinda makes sense because the energy threshold increases with zenith angle, and since the background is related to (but not given by) the charged cosmic ray spectrum that is a power-law and falls steeply, we also expect the background rate to change.
Let’s have a look at the dependence we get for this configuration used here (Hillas reconstruction, standard cuts, see H.E.S.S. release notes for more information).
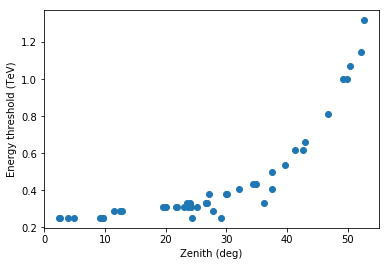
[9]:
x = obs_table["ZEN_PNT"]
y = obs_table["SAFE_ENERGY_LO"]
plt.plot(x, y, "o")
plt.xlabel("Zenith (deg)")
plt.ylabel("Energy threshold (TeV)");
[10]:
x = obs_table["ZEN_PNT"]
y = obs_table["EVENT_COUNT"] / obs_table["ONTIME"]
plt.plot(x, y, "o")
plt.xlabel("Zenith (deg)")
plt.ylabel("Rate (events / sec)")
plt.ylim(0, 10);
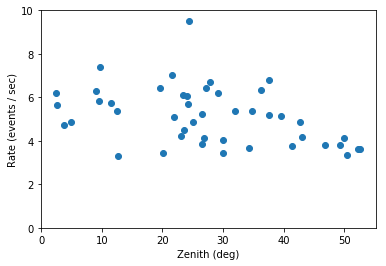
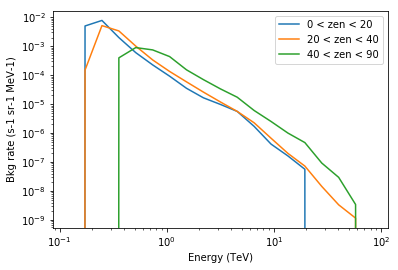
The energy threshold increases, as expected. It’s a bit surprising that the total background rate doesn’t decreases with increasing zenith angle. That’s a bit of luck for this configuration, and because we’re looking at the rate of background events in the whole field of view. As shown below, the energy threshold increases (reducing the total rate), but the rate at a given energy increases with zenith angle (increasing the total rate). Overall the background does change with zenith angle and that dependency should be taken into account.
The remaining scatter you see in the plots above (in energy threshold and rate) is due to dependence on telescope optical efficiency, atmospheric changes from run to run and other effects. If you’re interested in this, 2014APh….54…25H has some infos. We’ll not consider this futher.
When faced with the question whether and how to model the zenith angle dependence, we’re faced with a complex optimisation problem: the closer we require off runs to be in zenith angle, the fewer off runs and thus event statistic we have available, which will lead do noise in the background model. The choice of zenith angle binning or “on-off observation mathching” strategy isn’t the only thing that needs to be optimised, there’s also energy and offset binnings and smoothing scales. And of course good settings will depend on the way you plan to use the background model, i.e. the science measurement you plan to do. Some say background modeling is the hardest part of IACT data analysis.
Here we’ll just code up something simple: make three background models, one from the off runs with zenith angle 0 to 20 deg, one from 20 to 40 deg, and one from 40 to 90 deg.
[11]:
zenith_bins = [
{"min": 0, "max": 20},
{"min": 20, "max": 40},
{"min": 40, "max": 90},
]
def make_model(observations):
ebounds = np.logspace(-1, 2, 20) * u.TeV
offset = sqrt_space(start=0, stop=3, num=10) * u.deg
estimator = BackgroundModelEstimator(ebounds, offset)
estimator.run(observations)
return estimator.background_rate
def make_models():
for zenith in zenith_bins:
mask = zenith["min"] <= obs_table["ZEN_PNT"]
mask &= obs_table["ZEN_PNT"] < zenith["max"]
obs_ids = obs_table["OBS_ID"][mask]
observations = data_store.get_observations(obs_ids)
yield make_model(observations)
[12]:
%%time
models = list(make_models())
CPU times: user 1.87 s, sys: 59.1 ms, total: 1.93 s
Wall time: 1.94 s
[13]:
models[0].plot()
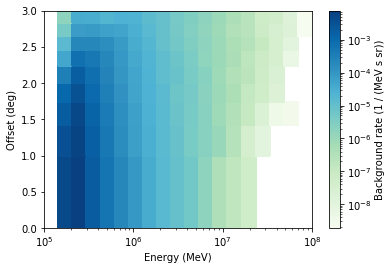
[14]:
models[2].plot()
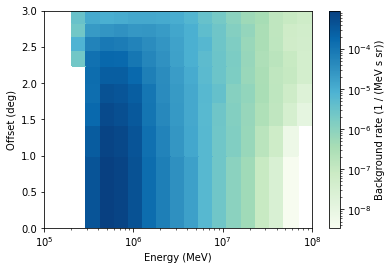
[15]:
energy = models[0].data.axis("energy").center.to("TeV")
y = models[0].data.evaluate(energy=energy, offset="0.5 deg")
plt.plot(energy, y, label="0 < zen < 20")
y = models[1].data.evaluate(energy=energy, offset="0.5 deg")
plt.plot(energy, y, label="20 < zen < 40")
y = models[2].data.evaluate(energy=energy, offset="0.5 deg")
plt.plot(energy, y, label="40 < zen < 90")
plt.loglog()
plt.xlabel("Energy (TeV)")
plt.ylabel("Bkg rate (s-1 sr-1 MeV-1)")
plt.legend();
Index tables¶
So now we have radially symmetric background models for three zenith angle bins. To be able to use it from the high-level Gammapy classes like e.g. the MapMaker though, we also have to create a HDU index table that declares which background model to use for each observation.
It sounds harder than it actually is. Basically you have to some code to make a new astropy.table.Table. The most tricky part is that before you can make the HDU index table, you have to decide where to store the data, because the HDU index table is a reference to the data location. Let’s decide in this example that we want to re-use all existing files in $GAMMAPY_DATA/hess-dl3-dr1 and put all the new HDUs (for background models and new index files) bundled in a single FITS file called
hess-dl3-dr3-with-background.fits.gz, which we will put in $GAMMAPY_DATA/hess-dl3-dr1.
[16]:
filename = "hess-dl3-dr3-with-background.fits.gz"
# Make a new table with one row for each observation
# pointing to the background model HDU
rows = []
for obs_row in data_store.obs_table:
# TODO: pick the right background model based on zenith angle
row = {
"OBS_ID": obs_row["OBS_ID"],
"HDU_TYPE": "bkg",
"HDU_CLASS": "bkg_2d",
"FILE_DIR": "",
"FILE_NAME": filename,
"HDU_NAME": "BKG0",
}
rows.append(row)
hdu_table_bkg = Table(rows=rows)
[17]:
# Make a copy of the original HDU index table
hdu_table = data_store.hdu_table.copy()
hdu_table.meta.pop("BASE_DIR")
# Add the rows for the background HDUs
hdu_table = vstack([hdu_table, hdu_table_bkg])
hdu_table.sort("OBS_ID")
[18]:
hdu_table[:7]
[18]:
| OBS_ID | HDU_TYPE | HDU_CLASS | FILE_DIR | FILE_NAME | HDU_NAME | SIZE |
|---|---|---|---|---|---|---|
| int64 | str6 | str9 | str4 | str36 | str6 | int64 |
| 20136 | events | events | data | hess_dl3_dr1_obs_id_020136.fits.gz | events | 414720 |
| 20136 | psf | psf_table | data | hess_dl3_dr1_obs_id_020136.fits.gz | psf | 118080 |
| 20136 | edisp | edisp_2d | data | hess_dl3_dr1_obs_id_020136.fits.gz | edisp | 377280 |
| 20136 | bkg | bkg_2d | hess-dl3-dr3-with-background.fits.gz | BKG0 | -- | |
| 20136 | gti | gti | data | hess_dl3_dr1_obs_id_020136.fits.gz | gti | 5760 |
| 20136 | aeff | aeff_2d | data | hess_dl3_dr1_obs_id_020136.fits.gz | aeff | 11520 |
| 20137 | events | events | data | hess_dl3_dr1_obs_id_020137.fits.gz | events | 216000 |
[19]:
# Put index tables and background models in a FITS file
hdu_list = fits.HDUList()
hdu = fits.BinTableHDU(hdu_table)
hdu.name = "HDU_INDEX"
hdu_list.append(hdu)
hdu = fits.BinTableHDU(data_store.obs_table)
hdu_list.append(hdu)
for idx, model in enumerate(models):
hdu = model.to_fits()
hdu.name = "BKG{}".format(idx)
hdu_list.append(hdu)
print([_.name for _ in hdu_list])
import os
path = (
Path(os.environ["GAMMAPY_DATA"])
/ "hess-dl3-dr1/hess-dl3-dr3-with-background.fits.gz"
)
hdu_list.writeto(str(path), overwrite=True)
['PRIMARY', 'HDU_INDEX', 'OBS_INDEX', 'BKG0', 'BKG1', 'BKG2']
[20]:
# Let's see if it's possible to access the data
ds2 = DataStore.from_file(path)
ds2.info()
obs = ds2.obs(20136)
obs.events
obs.aeff
obs.bkg.plot()
Data store:
HDU index table:
BASE_DIR: /Users/adonath/data/gammapy-datasets/hess-dl3-dr1
Rows: 630
OBS_ID: 20136 -- 47829
HDU_TYPE: ['aeff', 'bkg', 'edisp', 'events', 'gti', 'psf']
HDU_CLASS: ['aeff_2d', 'bkg_2d', 'edisp_2d', 'events', 'gti', 'psf_table']
Observation table:
Observatory name: 'N/A'
Number of observations: 105
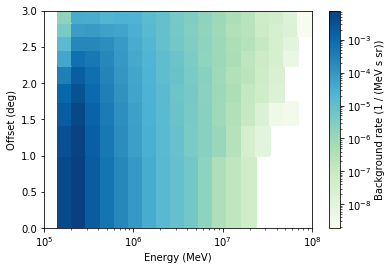
Exercises¶
- Play with the parameters here (energy binning, offset binning, zenith binning)
- Try to figure out why there are outliers on the zenith vs energy threshold curve.
- Does azimuth angle or optical efficiency have an effect on background rate?
- Use the background models for a 3D analysis (see “hess” notebook).
[21]: